




















 ABOUT
ABOUT TECHNOLOGY
TECHNOLOGY BUSINESS
BUSINESS IR
IR CAREERS
CAREERS



얼굴 인식 기술에 관하여: 컴퓨터가 당신을 알아보는 방법
-
 Dylan Han
Dylan Han - 2022.09.28
얼굴 인식 기술에 관하여: 컴퓨터가 당신을 알아보는 방법
들어가며

[그림 1] 영화 미션 임파서블: 고스트 프로토콜의 한 장면
범죄나 SF 영화를 보면 수사 기관이 CCTV 등으로 행인들의 얼굴을 실시간으로 수집해서 범죄자를 찾아내는 장면들을 한 번쯤 보셨을 겁니다.
그런데 이런 장면이 더는 영화 속에서만 존재하는 상상 속 이야기가 아니라는 것 알고 계시나요?
얼굴 인식 기술은 이미 전 세계적으로 범죄 수사, 출입 통제 등 다양한 분야에서 활용되고 있습니다.
얼굴 인식 기술 강국인 중국은 2015년부터 얼굴 인식 기술 기반 영상 감시 시스템인 ‘텐왕’을 도입하여 현재까지 2,000명이 넘는 범죄자를 검거했습니다.
미국 역시 FBI에서 2011년부터 얼굴 인식 기술을 차세대 신원 확인 시스템으로 선정하여 범죄 수사 최전선에서 활용하고 있습니다.
최근 워싱턴 의사당에 난입한 시위대 70명을 검거한 사례도 있었죠.
2020년대 들어서는 범죄 수사와 같은 공공 부문뿐만 아니라 민간 부문에서도 얼굴 인식 기술에 대한 수요가 폭발적으로 증가했습니다.
코로나 19가 전 세계적으로 유행하면서 비대면 서비스의 필요성이 대두했기 때문입니다. 이에 따라 우리는 실생활과 가까운 은행, 편의점 등에서도 얼굴 인식 기술을 마주칠 수 있게 되었죠.
본문에서는 이처럼 뜨거운 관심을 받고 있는 얼굴 인식 기술에 대한 설명과 동작 과정에 대해서 다룹니다.
이를 통해 얼굴 인식 기술에 대해 궁금하셨던 분들이나 얼굴 인식 기술 도입을 고민하는 분들께서 얼굴 인식 기술을 이해하는 데 도움이 되고자 합니다.
얼굴 인식 기술은 무엇인가요?
정의
얼굴 인식 기술이란 말 그대로 사람의 얼굴을 통해 신원을 확인하는 기술입니다. 얼굴 인식 기술을 활용한 인식 체계를 얼굴 인식 시스템이라고 합니다. 이를테면 얼굴 인식 기술로 범죄자를 탐색하는 체계는 얼굴 인식 기반 수사(Investigation system) 시스템이라고 할 수 있으며 출입국 여행객을 확인하는 체계는 얼굴 인식 기반 출입국 통제 시스템(Access Control System)이라고 할 수 있습니다.
얼굴 인식 기술의 분류
얼굴 인식 기술은 크게 다음과 같이 두 종류로 분류됩니다.

[표 1] 얼굴 인식 기술의 분류
1:1 Verification
1:1 얼굴 인식 기술이란 현재 카메라에 인식된 한 명의 사람을 시스템에 등록된 한 명의 사람의 얼굴 이미지와 비교하여 두 얼굴 이미지가 동일 인물인지 아닌지 판단하는 기술입니다.
1:1 얼굴 인식 기술은 “1:1 검증(1:1 Verification) 기술”으로도 불립니다.
iPhone Face ID가 1:1 얼굴 인식 기술을 활용한 좋은 예시입니다. Face ID를 예시로 1:1 얼굴 인식 기술의 메커니즘을 간단하게 살펴보겠습니다.
“먼저 휴대폰의 주인이 본인의 얼굴을 시스템에 등록합니다. 이후 시스템은 휴대폰 잠금 해제를 요청받을 때마다 내장된 카메라를 통해 카메라 앞의 얼굴을 촬영합니다. 촬영한 얼굴 이미지와 시스템에 등록된 휴대폰 주인의 얼굴 이미지와 일대일 비교하여 잠금 해제 여부를 판단합니다.”
1:N Identification
1:N 얼굴 인식 기술이란 현재 카메라에 인식된 한 명의 사람을 시스템에 등록된 다수의 얼굴 이미지들과 비교하여 인식된 얼굴이 등록된 얼굴 중 누구와 가장 유사한지 판단하는 기술입니다.
1:N 얼굴 인식 기술은 “1:N 식별 기술(1:N Identification)”으로도 불립니다.
CUBOX의 경우 1:N 얼굴 인식 기술을 활용하여 오피스 출입 통제를 관리하고 있습니다. CUBOX 출입 통제 시스템을 예시로 1:N 인식 기술의 메커니즘을 간단하게 살펴보겠습니다.
“먼저 CUBOX 전사 직원들의 얼굴 이미지를 시스템에 등록합니다. 이후 시스템은 출입 통제 단말기 앞에 사람이 인식될때 마다 그 사람의 얼굴을 촬영합니다. 촬영한 얼굴 이미지와 시스템에 등록된 CUBOX 직원들의 사진 모두와 일대다 비교하여 출입 여부를 결정합니다.”
얼굴 인식 기술의 사용 이유
얼굴 인식 기술이 주목받고 있는 이유는 얼굴 인식 기반 시스템이 기존의 대면 시스템과 비교했을 때 비용, 안정성, 사용자 편의 측면에서 이점이 있기 때문입니다.
비용 이점
대면 기반의 신원 확인 시스템을 얼굴 인식 기반 시스템으로 대체할 경우 신원 확인을 위해 투입되는 인건비나 서류 비용(Paperwork Cost) 등을 절감시킬 수 있습니다.
공항과 같이 대규모의 신원 확인이 필요한 상황에서 이러한 이점은 더욱 두드러집니다.
출입국 심사 직원 한 명당 하루에 처리할 수 있는 인원은 한계가 있기 때문에 원활한 출입국 관리를 위해 대규모의 인원을 투입해야 합니다. 이를 위해 많은 인건비와 교육 비용을 지불해야 합니다.
여기에 이용객 수 증감률이나 계절성 등을 고려하면 인력 배치나 비용 계획에 대한 고민은 더욱 깊어지죠.
얼굴 인식 기반 출입국 시스템은 설치하고 나면 알고리즘 성능에 따라 심지어 하나의 기기에서 모든 여행객의 출입국 심사를 담당할 수도 있습니다. 또한 추가적인 처리 인원 당 들어가는 비용(Unit cost)도 거의 없습니다.
안정성 이점
최신 얼굴 인식 기술은 사람의 인식 정확도인 97.53%를 훌쩍 넘어 99.9% 이상의 놀라운 정확도를 기록하고 있습니다.
이에 더해 사람의 인식 정확도는 개인차가 있고 환경, 컨디션 등에 따라 매번 달라질 수 있지만, 얼굴 인식 기술은 이러한 변동성이 없으므로
언제나 안정적으로 높은 수준의 얼굴 인식 서비스를 제공할 수 있습니다.
사용자 편의 이점
서비스 소비자 관점에서 기존 대면 기반 서비스가 얼굴 인식 기반 서비스로 대체될 경우 기존의 서면 절차와 같은 복잡한 단계가 생략되어 인증을 위한 시간이 많이 감소합니다.
또한 인증을 위한 신분증, 키 카드와 같은 인증 수단을 따로 발급받거나 관리할 필요가 없어 기존 대면 서비스보다 사용자 편의가 뛰어나다고 볼 수 있습니다.
기타
이외에도 얼굴 인식 기술은 신원 인증을 위한 언어 행위나 신체 접촉이 필요 없이 지금과 같은 판데믹 상황에서 위생적이고 안전한 신원 인증 기술이라고 할 수 있습니다.
얼굴 인식 기술 프로세스
지금부터 얼굴 인식 기술이 어떤 과정을 거쳐 사람의 얼굴을 인식하는지 알아보도록 하겠습니다. 얼굴 인식은 크게 네 단계로 이루어집니다.
이 장에서는 얼굴 인식 기술의 단계 별 작동 원리에 대해 알아보도록 하겠습니다

[그림 2] 얼굴 인식 기술 프로세스
얼굴 탐지(Face Detection) 단계

[그림 3] 얼굴 탐지: 전체 이미지 중 얼굴 부분을 찾아내는 작업
정의
얼굴 탐지 단계(Face Detection)는 전체 이미지 중 얼굴 부분을 탐지하고 잘라내는 과정입니다.
얼굴 인식 시스템이 인식 대상을 촬영하게 되면 얼굴 부분 뿐만 아니라 배경이나 사물 등이 포함된 전체 이미지가 촬영됩니다.
사실 전체 이미지 내에서 얼굴을 제외한 다른 부분은 얼굴 인식에 불필요할 뿐만 아니라 오히려 방해되는 요소입니다.
따라서 얼굴 탐지 단계에서는 이러한 요소들을 제거하고 얼굴 부분을 추려낸 새로운 이미지를 시스템에 전달하여 얼굴 인식의 정확도를 높이는 역할을 합니다.
얼굴 탐지 메커니즘
그렇다면 컴퓨터는 전체 이미지에서 얼굴 부분을 어떻게 찾아낼까요? 이 역할은 딥러닝 기반 얼굴 탐지 알고리즘이 담당합니다.
딥러닝 기반 얼굴 탐지 알고리즘은 딥러닝 모델에 대량의 학습 이미지를 제공하여 모델 스스로 전체 이미지 속에 얼굴 부분을 찾도록 학습된 알고리즘입니다.
딥러닝 모델의 얼굴 탐지 학습 과정은 다음과 같이 네 단계로 이루어집니다.

[그림 4] 얼굴 탐지 딥러닝 모델 학습 프로세스
학습 이미지 준비
여느 딥러닝 모델과 마찬가지로 얼굴 탐지 딥러닝 모델 또한 모델 학습에 필요한 이미지를 준비해야 합니다. 얼굴 탐지 모델인 만큼 이미지 내 얼굴이 포함된 최대한 많은 수의 이미지를 준비할수록 좋습니다.
학습 이미지 라벨링
준비된 학습 이미지 내 얼굴 영역에 라벨링을 해줍니다. 라벨링이란 쉽게 말해서 딥러닝 모델에게 ‘이 이미지에서 얼굴 영역은 여기야’라고 정답을 알려주는 것입니다.
실제 라벨링 과정에서는 수작업으로 이미지 내 얼굴 영역의 좌표값을 찾은 후 [이미지 이름 - 좌표값] 등의 형태로 짝지어 json과 같은 파일로 저장하게 됩니다.
좌표값은 탐지한 얼굴의 [좌상단,우하단] 위치 혹은 [얼굴 정중앙 좌표, 너비, 높이] 등 모델 별 자유로운 형식으로 반환할 수 있습니다.
라벨링은 방대한 이미지에 대해 정교한 수작업이 필요하기 때문에 학습 데이터 구축의 주요 난관 중 하나로 그 악명이 자자합니다.
그럼에도 정교한 라벨링은 딥러닝 모델이 올바른 학습을 하기 위해 반드시 필요한 과정입니다.
라벨링이 제대로 되지 않은 경우 딥러닝 모델이 이미지 내 엉뚱한 부분을 얼굴로 간주하고 학습하여 전체 얼굴 인식 알고리즘 정확도의 심각한 손상을 줄 수 있기 때문입니다.
얼굴 영역 예측
준비된 학습 이미지를 딥러닝 모델에 입력하면 딥러닝 모델이 예측한 얼굴 영역의 좌표가 반환 됩니다.
학습의 초반 단계에서는 다소 엉뚱한 영역을 얼굴이라고 예측할 수 있습니다. 그러나 손실 계산 및 업데이트 과정을 수없이 거쳐 마침내 실제 얼굴 영역과 같거나 유사한 영역을 찾아낼 수 있도록 모델이 발전하게 됩니다.
손실 계산 및 재학습
딥러닝이 예측한 얼굴 영역과 실제로 라벨링 된 얼굴 영역을 비교해서 틀린 정도를 측정하고 이를 바탕으로 모델이 더 나은 예측력을 가지도록 학습을 강화하는 단계입니다.
틀린 정도를 측정하는 방법은 대표적으로 IOU를 사용합니다.

[그림 5] IOU: 두 영역의 겹침 정도를 측정하는 지표
IOU란 두 영역 간 공통 부분이 얼마나 많은지 나타내는 지표입니다. IOU는 0~1 사이의 범위를 가집니다.
두 영역이 겹치는 부분이 많을수록 IOU가 1에 가깝죠. 이를 얼굴 탐지 알고리즘에 적용해 얼굴 탐지 알고리즘의 손실을 계산할 수 있습니다.
딥러닝이 예측한 얼굴 영역과 라벨링 된 얼굴 영역의 IOU를 측정한 이후 IOU가 0에 가까울수록 손실이 커지게 손실함수를 설계하면 됩니다.
결국 딥러닝 모델은 손실을 최소화하는 방식으로 학습하기 때문에 손실을 줄이기 위해서는 IOU를 1에 가깝도록 학습을 하고
이는 결과적으로 딥러닝이 예측한 얼굴 영역이 실제 얼굴 영역과 가깝게 탐지하도록 학습하는 효과가 있습니다.
정리해보면 얼굴 탐지 단계는 전체 이미지 내 얼굴 영역만을 추출하는 역할을 합니다. 이 역할은 전체 이미지 중 인식에 불필요한 부분을 제거해줌으로써 전체 얼굴 인식 시스템의 정확도를 높이는데 기여합니다. 얼굴 탐지 알고리즘은 딥러닝 기반 알고리즘을 주로 사용합니다. 대표적인 딥러닝 기반 얼굴 탐지 알고리즘은 TinaFace, SCRFD 등이 있습니다.
얼굴 정렬 단계

[그림 6] 얼굴 이미지 전처리 과정
정의
얼굴 정렬 단계는 획득한 얼굴 이미지의 위치나 각도를 조정하여 정면을 응시하는 얼굴(Frontal Face) 이미지로 변환하는 단계입니다.
얼굴 정렬 메커니즘은 얼굴 탐지 메커니즘과 마찬가지로 얼굴 특징 추출 모델이 좀 더 정확한 생체 정보를 추출할 수 있도록 돕는 역할을 합니다.
얼굴 특징 추출 모델은 주로 정면 이미지를 이용하여 학습되어 있기 때문에 각도나 위치가 변함에 따라 성능이 크게 좌우될 수 있습니다.
따라서 얼굴 정렬 단계는 각도나 위치가 제각각인 이미지들을 정면 이미지 형태로 정규화(Normalize)하여 이러한 변화로 발생하는 성능 저하를 예방하는 역할을 합니다.
얼굴 정렬 메커니즘
얼굴을 정규화시키는 대표적인 방법은 얼굴의 랜드마크를 이동시키는 방법입니다. 얼굴 랜드마크란 눈 코 입과 같은 얼굴의 주요 부위를 말합니다.

[그림 7] 얼굴 랜드마크의 위치 (출처:Media Alliance)
얼굴 랜드마크 위치는 얼굴 탐지 단계에서 얻을 수 있습니다. 얼굴 탐지 알고리즘은 학습 시 얼굴 위치 탐지뿐 아니라 랜드마크 탐지 학습을 병행해서 하게 됩니다.
따라서 이미지를 얼굴 탐지 알고리즘에 넣게 되면 딥러닝이 예측한 얼굴 영역 좌표와 랜드마크 위치가 좌표 형태로 반환되게 됩니다.
얼굴 정렬 단계에서는 반환된 랜드마크를 이용하여 얼굴을 정렬하는데요.
정렬 방법은 양 눈의 중심점 간의 각도를 구하고 해당 각도대로 전체 이미지를 회전 시키는 방법과 이상적인 랜드마크 위치 값을 좌표로 고정해둔 다음,
현재 랜드마크 위치값을 이상적인 위치 값으로 대응 시키는 함수를 찾아 모든 픽셀 값을 해당 함수에 적용하여 아파인 변환(Affine Transformation)시키는 방법 등이 있습니다.
정리해보면 얼굴 정렬 단계는 다양한 각도와 위치를 가지는 얼굴 이미지들을 얼굴 특징 추출 모델이 선호하는 형태의 얼굴 이미지로 변환하여 더욱 정확한 얼굴 특징을 추출할 수 있도록 돕는 역할을 합니다.
얼굴 특징 추출 단계

[그림 8] 얼굴 이미지와 해당 이미지에서 추출한 얼굴 템플릿
정의
얼굴 특징 추출 단계는 전처리 된 이미지를 입력값으로 받아 얼굴 템플릿을 생성하는 단계입니다. 얼굴 특징 추출 단계를 얼굴 템플릿 생성 단계라고도 부릅니다.
얼굴 템플릿이란 딥러닝 모델이 얼굴 이미지 내 특징들을 추출하여 숫자 데이터로 나타낸 것입니다.
사람의 얼굴은 서로 다른 특징을 가지기 때문에 개인의 얼굴 템플릿은 전부 다른 숫자들로 채워져 있습니다.
즉, 얼굴 템플릿은 개인만이 가질 수 있는 고유의 생체 정보라고 할 수 있습니다.
얼굴 템플릿 생성의 목적
얼굴 인식 시스템은 오로지 얼굴 템플릿에 의존하여 인식 작업을 수행합니다.
얼굴 인식 시스템은 기존 인식 시스템들과 인식 원리가 같습니다.
기존 인식 시스템의 경우 인식 대상이 주민등록번호, 여권 번호 등 고유 정보를 제출하면 시스템에 등록된 정보와 비교하여 정오(Genuine/Imposter) 여부를 판단합니다.
얼굴 인식 시스템도 마찬가지입니다. 다만 고유 정보로 얼굴 템플릿을 사용할 뿐이죠. 결론적으로 얼굴 인식 시스템의 보안 수준은 바로 얼굴 특징 추출 단계에서 얼마나 정교한 얼굴 템플릿을 생성할 수 있는가에 달렸다고 봐도 무방합니다.
얼굴 특징 추출 메커니즘
얼굴 템플릿은 딥러닝 기반 특징 추출 모델로부터 획득합니다.
얼굴 인식 시스템에 사용되는 특징 추출 모델은 이미지 분류 등에 사용되는 일반적인 특징 추출 모델보다 높은 수준의 분별 성능이 필요합니다.
그 이유는 얼굴 이미지가 갖는 높은 난이도 때문입니다.
고양이 이미지와 자동차 이미지를 분류하는 작업은 두 개체 간 크기, 질감, 구성 요소 등이 서로 많이 달라 구별이 쉽습니다.
그러나 사람의 얼굴은 대부분 얼굴 크기와 눈,코,입 위치 등이 서로 비슷하므로 개체 간 구별이 어렵습니다. 심지어 같은 인종 / 나이 등 추가사항이 더해지면 구별 난이도가 더 올라갑니다.
이에 더해 얼굴 이미지는 개체 간 구별이 어려울 뿐 아니라 동일 인물의 다른 이미지 간 구별 역시 어렵습니다. 인간은 다른 개체와는 달리 얼굴의 변화가 많이 발생합니다.
다음과 같이 얼굴 변화를 일으키는 다양한 요인이 존재하기 때문입니다.
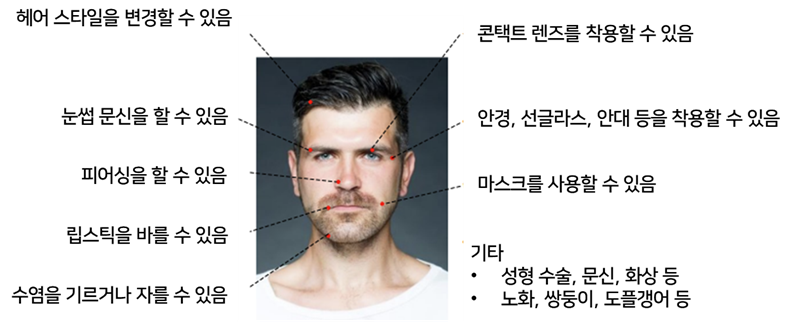
[그림 9] 얼굴 변화를 일으키는 다양한 요인들
따라서 제대로 된 얼굴 인식이 이루어지기 위해서는 추출된 얼굴 템플릿이 다음과 같은 특징을 가져야 합니다.
● 개체 간 분별(Interclass Separability)이 잘 되어야함
● 동일 개체 간 긴밀성(Intraclass Compactness)이 높아야 함
이러한 템플릿을 만들기 위하여 얼굴 특징 추출 모델은 특별한 손실 함수를 사용하여 학습 합니다.
기존의 일반적인 분류 모델은 교차 엔트로피 손실 함수(Cross entropy Loss)와 같은 소프트맥스(Softmax) 기반 손실 함수들을 학습에 사용합니다.
소프트맥스 기반 손실 함수는 동일 개체 간 긴밀성은 전혀 고려하지 않은 손실 함수 입니다. 쉽게 말해 기존 분류 모델로 얼굴 인식을 한다고 할 때 동일인이 짙은 화장을 하고 나타나면 인식하지 못할 확률이 높습니다.
얼굴 인식 특징 추출 모델의 경우 Center Loss, Triplet Loss와 같이 거리 기반의 손실 함수를 사용하여 학습(Metric Learning)하거나,
Cosface, Arcface와 같이 기존 Softmax에 각도 개념을 도입한 손실 함수를 사용하여 학습(Angular Margin Learning)하는 등 동일 개체 간 긴밀성을 높이기 위한 학습을 합니다.
학습의 아이디어는 간단합니다. 같은 사람의 여러 템플릿을 추출한 다음 템플릿 간 거리/각도가 멀수록/클수록 더 큰 손실 함수를 부여하여 결국 모델이 같은 사람의 템플릿 간 거리/각도를 가깝게/작게 만들도록 유도하는 것입니다.

[그림 10] 학습 방법에 따른 템플릿 분포 변화
[그림 10] 은 같은 이미지에 대해 각자 다른 손실 함수로 학습한 모델의 분류 결과를 보여줍니다.
그림 상의 각 점은 얼굴 템플릿을 나타내며 점들의 색은 서로 다른 개체를 나타냅니다.
기존 소프트 맥스 손실 함수 기반 학습보다 거리/각도 기반 학습은 같은 개체에 해당하는 템플릿간 밀집도가 높고 다른 개체 간 거리 역시 멀리 떨어져 있음을 볼 수 있습니다.
얼굴 매칭 단계
정의
얼굴 매칭 단계는 둘 이상의 얼굴 템플릿을 비교하여 해당 템플릿들이 동일인인지 아닌지를 최종적으로 판단해내는 단계입니다.
비교에는 유사도 점수가 사용됩니다. 유사도 점수란 말 그대로 두 템플릿이 얼마나 유사한지를 측정하는 지표입니다.
측정한 유사도 점수가 특정 임계값을 넘게 되면 동일인, 넘지 못하면 다른 사람으로 판단하는 방식으로 진행됩니다.
유사도 점수 측정 방법
앞서 얼굴 템플릿은 알 수 없는 숫자들로 채워진 데이터라고 했습니다.
숫자 데이터는 벡터의 형태로 나타낼 수 있으므로 얼굴 템플릿은 n 차원 벡터라고 볼 수 있습니다.
여기에 두 벡터 간의 유사도를 측정하는 기존의 기법(유클리디안 거리, 코사인 유사도 등)들을 적용하면 두 얼굴 템플릿 간 유사도를 측정할 수 있습니다.
유사도 측정 예시: 코사인 유사도

[그럼 11] 벡터 간 코사인 유사도 측정
길이가 같은 벡터 A, B, C가 있다고 가정할 때 벡터 A와 C 중 벡터 B와 더 가까운 건 어떤 것일까요?
각 벡터의 길이가 같으므로 벡터 사이 끼인각이 작을수록 두 벡터가 가깝다고 할 수 있겠죠.
따라서 θAB가 θBC 보다 작으므로 A가 B와 더 가깝다고 할 수 있습니다.
즉 Cos θAB가 Cos θBC보다 큽니다(0θ). A,B,C가 얼굴 템플릿이라고 생각해보면 C보다는 A가 B와 동일인일 확률이 높다는 것입니다.
임계값이란 무엇인가요?
템플릿 간 유사도 점수 측정이 완료되면 이제 최종적으로 템플릿들이 동일인인지 타인인지 판단해야 합니다.
그렇다면 유사도 점수가 몇 점이 나와야 동일인이라고 판단할 수 있을까요?
예를 들어 유사도 점수를 0~100점으로 표준화했을 때 90점이면 동일인이라고 볼 수 있을까요? 89점은 어떤가요? 89.9999점은 어떤가요?
이처럼 기준이 모호하기 때문에 정확히 “유사도 점수가 몇 점 이상일 때 동일인으로 판단한다”라는 기준이 필요합니다.
임계값이 바로 기준의 역할을 합니다.
즉 유사도 점수가 임계값 이상이면 시스템이 최종적으로 두 템플릿이 동일인으로 판단하는 것이죠. 결론적으로 템플릿 간 유사도 점수를 측정하고 해당 점수가 임계값을 넘었는지 판단하는 전 과정을 통틀어 얼굴 매칭 단계라고 합니다.
임계값은 어떤 값으로 설정해야 하나요?
임계값은 관리자가 임의로 설정할 수 있습니다.
임계값을 너무 낮게 설정할 경우 등록되지 않은 사용자가 쉽게 시스템을 통과할 수 있게 될 것입니다.
반면 임계값을 너무 높게 설정할 경우 등록된 정상적인 사용자조차 시스템을 통과할 수 없게 될 것입니다.
따라서 원하는 보안, 편의 수준에 맞추어 적절한 임계값을 설정해야 합니다.
적절한 임계값을 설정하는 방법은 이후에 개제할 아티클에서 더 자세히 다뤄보도록 하겠습니다.
마치며
이번 글을 통해 얼굴 인식 시스템 종류와 탐지/정렬/추출/매칭에 이르는 얼굴 인식 시스템의 동작 과정에 대하여
알아보았습니다. 얼굴 인식 기술을 통하여 우리는 얼굴만을 가지고 신속하게 공항 출입국 심사대를 통과하고, 물건을 결제하는 등 영화 속에서나 가능하던 일들을 현실에서 누릴 수 있게 되었습니다.
이처럼 얼굴 인식 기술은 어느새 우리의 일상과 훌쩍 가까워졌습니다. 얼굴 인식 기술을 잘 활용한다면 전에 없던 편의와 효율성을 얻을 수도 있겠지만 잘못 사용하게 되면 프라이버시, 보안상의 중대한 위협이 될 수도 있습니다. 따라서 양날의 검과도 같은 얼굴 인식 기술을 적절히 취사 선택하기 위해서는 얼굴 인식 기술에 대한 전반적인 이해가 선행되어야 할 것입니다. 본문의 내용이 여러분이 얼굴 인식 기술에 대해 이해하시는데 도움이 되었으면 합니다.
긴 글 읽어주셔서 감사합니다
About CUBOX
CUBOX는 NIST에서 주관하는 얼굴 인식 대회인 FRVT(얼굴 인식 알고리즘 기업 테스트, Face Recognition Vendor Test)에서
1:1, 1:N 모두 세계 1위, 국내 1위 성적을 보유하고 있습니다.* 이러한 기술력을 인정 받아 인천공항, 정부 청사의 얼굴 출입 시스템을 직접 구축 및 운영하고 있습니다.
CUBOX AI LAB은 Face re-identification, Face detection, Face Mask Effect, Face Anti-Spoofing, Face parsing 등 얼굴 인식 및
컴퓨터 비전 기술 전반에 대한 독자적인 모델 연구를 진행하고 있으며, 관련 데이터셋 구축 사업 역시 진행하고 있습니다.
CUBOX AI LAB 연구에 대한 문의사항이 있으시거나 AI LAB과 함께 일하고 싶으신 분들은 언제든지 연락 주시기 바랍니다.
* 1:1 Verification Kiosk(21.11 기준), 1:N Identification Visa-Kiosk(21.09 기준), 1:N Investigation Visa-Kiosk(21.09 기준), 1:N Investigation Border-Border(21.09 기준), Paperless Travel(N=42,000, 21.10 기준)
Reference
Mei Wang, Weihong Deng, Deep Face Recognition: A Survey, CVPR, 2020
Tamir Israel, Facial Recognition at a Crossroads:Transformation at our Borders & Beyond, CIPPIC, 2020
Yandong Wen, at el. A Discriminative Feature Learning Approach for Deep Face Recognition, ECCV, 2016
JianKang Deng, at el. ArcFace: Additive Angular Margin Loss for Deep Face Recognition, CVPR, 2019
Patrick Grother, Face Recognition Vendor Test (FRVT) Part 3: Demographic Effects, NIST, https://nvlpubs.nist.gov/nistpubs/ir/2019/NIST.IR.8280.pdf




COPYRIGHT (c) 2022 CUBOX ALL RIGHTS RESERVED
개인정보취급방침