




















 ABOUT
ABOUT TECHNOLOGY
TECHNOLOGY BUSINESS
BUSINESS IR
IR CAREERS
CAREERS



3D Deep Learning 소개
-
 김태오
김태오 - 2022.11.09
3D Deep Learning 소개
들어가며
일상 속 흔히 사용되는 이미지(2D 데이터)는 딥러닝을 활용하여 image classification, object segmentation, object detection 등 상황에 따라 필요한 여러 task 를 수행할 수 있습니다. 더 나아가, 앞서 언급한 task 들은 기하학정보를 가지고 있는 3D 데이터에서도 적용될 수 있습니다. 3D 데이터에 대한 딥러닝의 활용은 자율주행, 로봇, 증강/가상 현실 등 다양한 분야로 확장될 수 있고, 자율주행을 위한 LiDAR 센서는 3D 데이터를 생성합니다. 그렇다면 3D 데이터는 어떻게 표현이 되고, 3D 데이터에 대한 classification, segmentation, detection 등은 어떻게 수행이 될까요? 이번 시간을 통해 3D 데이터와 3D 딥러닝에 대해 알아보도록 하겠습니다.
3D Data
표현 방법
3D 데이터를 표현하는 방법으로는 euclidean-structured data 와 non-euclidean data 가 있습니다. Euclidean data 는 2D 이미지 데이터와 같이 표현되는 grid-structured data 를 말하며, 그 예로 RGB-D, Voxel 등이 있습니다. 반면, non-euclidean data 는 non-euclidean 구조를 기반한다는 특징이 있으며, 대표적인 예로는 point cloud 와 mesh 등이 있습니다.

그림 1. 3D 데이터 (좌측부터 RGB-D, voxel, point cloud, mesh)
일반적으로, 3D 데이터는 voxel, mesh, point cloud 등으로 표현될 수 있습니다. Voxel 데이터 표현은 볼륨이 있는 2D 픽셀 표현의 확장으로 볼 수 있습니다. 딥러닝에서 voxel 데이터는 2D convolution 의 개념을 확장한 3D convolution 을 통하여 데이터 표현 변환 없이 voxel 데이터 그대로 사용될 수 있다는 점이 있지만, 세밀한 데이터 표현을 할수록 메모리 관점에서 비용이 비싸다는 단점을 가지고 있습니다. 반면, mesh 와 point cloud 데이터 표현은 메모리 관점에서 효율적인 데이터 표현입니다. Mesh 데이터는 2D 삼각형이 서로 연결된 형태로 3D 공간을 만듦으로써 3D 공간을 표현하며, 3D 렌더링에서 mesh 데이터 표현이 활용되는 것을 쉽게 찾아볼 수 있습니다. Point cloud 는 3D 공간 상의 x, y, z 좌표값으로 3D 대상을 표현합니다. Point cloud 데이터 표현은 3D 스캐너 혹은 3D 센서 등에서 사용되어집니다.
데이터셋
ModelNet40
ModelNet40 은 물체에 대한 3D CAD 모델로 구성된 데이터셋입니다. ModelNet40 은 40 종의 카테고리에 대하여 12,311 수의 데이터로 이루어져 있으며, 이 중 9,843 (80%) 는 훈련 데이터셋, 2,468 (20%) 는 테스트 데이터셋으로 구성되어있습니다. CAD 모델은 object file format (OFF) 으로 되어있으며, OFF 파일 (mesh) 은 point cloud 데이터로 변환되어 point cloud 기반 모델의 학습 데이터로 사용될 수 있습니다.


그림 2. ModelNet 데이터셋 (좌측부터 mesh, point cloud)
ShapeNet
ShapeNet [6] 은 약 3백만 개의 3D CAD 모델로 이루어진 데이터셋입니다. 모델 중, 220,000 개의 모델에 대해서는 3,135 종의 클래스로 분류되었습니다. ShapeNet 은 ShapeNetCore 와 ShapeNetSem 으로 나뉘어지는데, ShapeNetCore는 single clean 3D 모델로 구성되어있고, 수작업으로 annotation 이 검증된 데이터셋입니다. ShapeNetCore 는 55 종의 클래스에 대한 약 51,300 개의 3D 모델을 포함하고 있습니다. ShapeNetSem 은 270 종의 클래스에 대한 12,000 개의 모델로 구성되어있습니다.
3D Classification
Multi-view CNN

그림 . Multi-view CNN for 3D shape recognition
Multi-view CNN [2]은 다각도에 대한 사물의 이미지를 통해 CNN을 학습시키고, 각 각도에 대한 정보를 합쳐 추론을 하도록 설계되었습니다. 하나의 물체에 대하여 12 가지의 각도에 대한 물체의 렌더링된 이미지는 첫 번째 CNN을 각각 통과하고, 이에 대한 12 개의 출력은 element-wise maximum operation을 수행하는 view-pooling layer를 통하여 합쳐집니다.
View-pooling layer를 통해 합쳐진 정보는 두 번째 CNN의 입력으로 들어가며, 두 번째 CNN에서 나오는 출력을 통하여 클래스 별 예측을 진행합니다.
3D Classification & Segmentation
PointNet

그림 . Applications of PointNet
PointNet [3]은 voxelization 혹은 rendering 없이 raw point cloud (set of points) 를 입력으로 하여 classification, part segmentation, semantic segmentation 을 수행하는 네트워크입니다.
Point data는 unordered, unstructured 한 특징이 있기에, 논문에서는 unordered point 가 입력으로 들어오는 상황에 대하여 네트워크는 입력이 어떠한 순서로 오더라도 output 이 달라지지 않아야 한다고 말합니다. N 개의 points 가 입력으로 들어올 때, 입력 순서의 조합은 N! 개가 되는데, 모델은 N! permutations 에 invariant 해야 한다고 말합니다. 이러한 성질을 만족하기 위해 변수의 위치(순서)가 달라져도 결과가 같은 symmetric function 을 제시하였고, symmetric function 으로 max pooling 함수를 사용하였습니다.

그림 . PointNet Architecture
또한, 논문에서는 geometric transformations 에 대하여 invariance 해야 한다고 말합니다. 예를 들어, 회전 된 point cloud 가 입력으로 들어오더라도, classification 에 대한 예측 결과는 달라지지 않아야 된다고 말합니다. 이를 위하여 T-Net 이 그림 수식을 Loss 함수에 추가하여 A 라는 transformation matrix 를 예측하도록 합니다.
그림 . Regularization term
정리하자면, PointNet 의 T-Net 은 들어오는 point 에 대한 orthogonal matrix 를 예측하도록 설계되었고, mlp (multi-layer perceptron), max pooling 을 통하여 global feature 를 생성합니다. Classification task 는 global feature 정보를 통하여 이루어지며, 출력으로 k 개의 class 에 대한 예측값이 나오게 됩니다. Segmentation task 는 local feature 와 global feature 를 concatenate 한 정보를 이용하며, 이는 mlp 를 통해 n 개의 point 에 대하여 m 개의 category 를 예측하는 것으로 수행됩니다.
PointNet++
PointNet 은 point cloud data 를 다른 형태의 데이터로 변환하여 모델을 학습시키는 것이 아닌 point sets 을 그대로 사용한 것에 있어 큰 의미가 있었습니다. 하지만 PointNet 은 CNN 과 같이 local structure 를 이용하지 못한다는 점이 있었고, 이를 해결하는 PointNet++ [4] 모델이 발표되었습니다.

그림 . PointNet++ architecture
PointNet++ 는 다수의 set abstraction 으로 구성되어 있습니다. Set abstraction 은 sampling layer, grouping layer, pointnet layer 로 이루어져 있습니다.
Sampling layer 에서는 farthest point sampling (FPS) 를 통해 입력으로 들어오는 N 개의 점들 중 N’ 개의 점들을 중심점으로 선택합니다. 이 때, 중심점들은 N’ 개 만큼 샘플링 된 전체 점들의 서로 간의 Euclidean distance 가 가장 먼 점들을 의미합니다. 이렇게 서로 간의 거리가 가장 먼 점들을 선택하는 과정을 farthest point sampling (FPS) 이라고 합니다.
Grouping layer 에서는 중심점의 이웃한 점들을 묶어 하나의 local region 을 만드는 역할을 하고, PointNet layer 는 mini-PointNet 을 사용하여 local region pattern 을 feature vector 로 만드는 역할을 수행합니다.
더 나아가, PointNet++ 에서는 다양한 scale 을 가지는 feature 을 활용하여 학습을 수행하기 위한 고민을 했습니다. 그 배경은 입력으로 들어오는 point set 이 non-uniform density 를 가지는 특징이 있다는 것이었습니다.
예를 들어, dense data 를 통하여 학습된 모델은 sparse data 입력에 대한 generalization 이 안될 수가 있고, 그 반대로 sparse data 를 통하여 학습된 모델은 fine-grained local structures 를 인식하지 못할 수도 있습니다. 이러한 문제를 해결하기 위하여 multi-resolution grouping (MRG) 을 도입하였습니다.
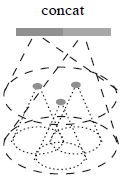
그림. Multi-resolution grouping (MRG)
MRG 는 두 개의 벡터를 concatenation 한 feature 를 사용하는데, 그림 . 왼쪽에 해당하는 벡터는 이전 레이어에서 얻은 features 를 종합한 것이고, 오른쪽에 해당하는 벡터는 local region 에 있는 모든 점들에 대하여 PointNet 을 통해 얻어지는 feature 입니다.
Segmentation task 를 수행하기 위해서 original points 를 얻는 과정이 필요한데, 이는 subsampled points 된 features 로 부터 original points 로 복원하는 방법을 사용하였습니다. Interpolated feature 는 이전 레이어의 점들에 대한 feature 에 1/거리값 이라는 weight 를 가해 interpolation 하여 얻습니다. Interpolated feature 는 set abstraction level 에서 skip-connection 을 통하여 오는 feature 와 concatenate 되어지고, 이는 부족할 수도 있는 정보를 보완해주는 역할을 합니다.
3D Object Detection
PointRCNN
PointRCNN [5] 은 raw point cloud 를 이용하는 object detection framework 입니다. PointRCNN 은 크게 두 단계(stage)로 구성되어 있습니다. 첫 번째 stage 에서는 3D bounding box 를 생성하고, 두 번째 stage 에서는 canonical 3D box refinement 를 수행합니다.

그림 . PointRCNN architecture
PointRCNN 은 PointNet++ 를 backbone 으로 사용하여 point-wise feature 를 얻습니다. Point-wise feature vector 는 bin-based 3D box generation 과 foreground point segmentation 을 거치게 됩니다.
Foreground point segmentation 은 3D box proposals 을 foreground points 으로 부터 생성을 합니다. Point-wise features 는 segmentation head 를 통하여 foreground mask 를 예측하는데 사용되고, box regression head 를 통하여 3D proposals 를 생성하는데 사용됩니다. 이 때, Point segmentation 을 위한 ground-truth segmentation mask 는 3D ground-truth boxes 를 통하여 알 수 있습니다. Foreground points 의 수는 background points 의 수에 비해 매우 작기에 저자는 focal loss 를 도입하여 class imbalance problem 을 해결하고자 했습니다.

그림 . Focal loss
Bin-based 3D bounding generation 은 box regression head 를 통하여 foreground point segmentation 으로 부터 3D proposals 을 얻습니다.
3D bounding box 는 LiDAR 좌표계에서 (x, y, z, h, w, l, θ) 으로 표현되는데, (x, y, z) 는 물체의 중앙점이고, (h, w, l) 은 물체의 크기, θ 는 물체의 head 방향을 의미합니다. Bin-based 3D box generation 에서는 loss 를 크게 center localization loss (x, y, z), size estimation loss (h, w, l), orientation loss (θ) 으로 나눕니다.
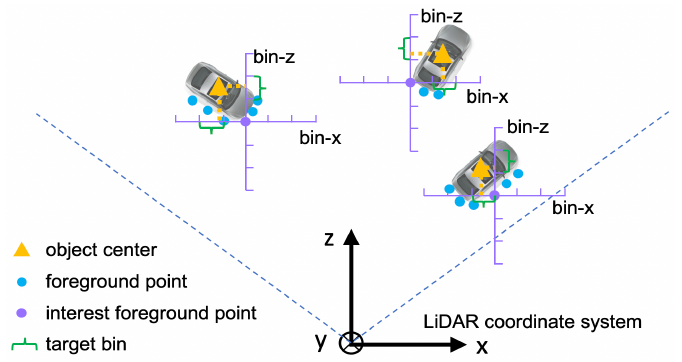
그림 . Bin-based localization
X, Z 축에 대한 좌표는 그림과 같이 표현됩니다. X, Z 축에 대한 중심점을 찾을 때, 찾는 범위를 S 라고 정의하고, 한 축을 동일한 간격 δ 으로 나눕니다.
X, Z 축에 대하여 물체의 중심 좌표가 어떤 bin 에 들어 있는지 찾기위하여 cross-entropy loss 기반 bin classification 을 수행하고, 찾은 bin 내에서의 미세 조정은 residual regression 을 통해서 이루어집니다.
Y 축에 대한 center y 값을 찾는 작업은 smooth L1 loss 를 이용하는데, 이 때, 찾으려고 하는 y 는 x, z 값을 찾는 범위 보다 훨씬 작은 범위 내에 존재합니다.
방향 θ 에 대한 loss 는 2π 를 n 개 의 bin 으로 나눈 후, 이것에 대하여 x, y localization loss 방법과 같이 진행을 합니다.
Object size (h, w, l) 에 대한 loss 는 각 클래스에 해당하는 물체의 평균 크기에 대한 residual 값을 smooth L1 loss 를 이용한 regression 을 합니다.
Bin-based 3D box generation 을 위한 loss 를 종합하면 그림과 같습니다.

그림 . 3D bounding box regression loss
생성된 proposals 중 고품질의 proposals 만 남기기 위하여 BEV 관점에서 0.85 IoU threshold 를 가지는 non-maximum suppression (NMS) 를 수행합니다. 이를 통하여 훈련 시에는 300 proposals 를 남기고, 추론 시에는 0.8 IoU threshold 를 가지는 NMS 를 진행하여 100 proposals 를 남깁니다.
이렇게 하여 얻은 3D bounding box proposals 의 box location 과 orientation 은 refine 되는데, 그 전에, point cloud region pooling 을 통하여 3D points 와 각 proposal 의 위치에 대한 point features 를 pool 합니다. 3D box proposal 의 h, w, l 값에 대해 상수 값을 더해줌으로써 확장된 box 를 만들고, point p = (x, y, z) 가 확장된 bounding box proposal 안에 위치하는지 판별합니다.
만약, point 가 box 안에 위치한다면 해당 features 를 box refinement 에 사용합니다.
Region pooling 을 통하여 가져온 points 를 대응되는 3D proposal 을 그림과 같이 canonical coordinate system 으로 변환해줍니다.

그림 . Canonical transformation
Canonical coordinate system 으로 변환하는 작업은 다음과 같은 규칙을 따릅니다. (1) 좌표계의 원점을 box proposal 의 중심점으로 하고, (2) local X’, Z’ 축을 지면에 평행하게 하되, X’ 축의 방향은 proposal 의 head direction 과 일치하게 하면서 Z’ 축은 X’ 축과 수직하게 놓고, (3) Y’ 축은 LiDAR coordinate system 과 동일하게 놓습니다.
Canonical coordinate system 은 box refinement 를 수행하는 것에 있어서 local spatial features 를 더 잘 학습하게 하기 위함이라고 합니다.
Canonical coordinate system 으로 변환된 point 는 local spatial feature 를 배우기에 적합하지만, 물체의 depth 정보를 잃은 상태입니다. 그래서, 이를 보완하기 위하여 LiDAR 센서에서 point 까지의 거리를 feature 에 더해줍니다.
결과적으로, local spatial features 와 extra features (laser reflection intensity, predicted segmentation mask, C-dimensional learned point feature representation) 을 concatenate 하고, 이를 fully-connected layers 에 넣어줍니다.
그리고 그 결과를 global features 와 concatenate 한 후 네트워크에 넣어줌으로써 confidence classification 과 box refinement 를 수행합니다.
Box proposal refinement 를 수행하기 위한 loss 는 다음과 같습니다. 먼저, ground-truth box 를 3D proposal 중 3D IoU 가 0.55 보다 큰 경우에 해당하는 것에 할당합니다.
3D proposals 와 3D ground-truth boxes 를 canonical coordinate system 으로 변환을 하고, center refinement 는 stage-1 에서의 bin-based localization 과 동일한 방법으로 수행합니다.
물체의 크기 역시 stage-1 과 같이 동일하게 진행하며, orientation 은 범위를 [-π/4, π/4] 으로 한정한 후, stage-1 과 같이 동일하게 진행합니다. 결과적으로, stage-2 에서의 loss 는 그림과 같습니다.

그림 . 3D bounding box refinement loss
마지막으로, BEV 에 대하여 IoU threshold 0.01 에 대한 NMS 을 적용하여 겹치는 bounding boxes 를 제거하고, object detection 을 위한 3D bounding boxes 를 생성합니다.
마치며
2D 이미지 데이터에 대한 딥러닝의 활용은 image classification 부터 시작하여 object detection, object segmentation 등 여러 task 로 급격히 발전하였습니다.
그러나, 2D 데이터는 3D 데이터와 비교했을 때 제한된 정보를 가지고 있다는 점은 딥러닝을 활용하여 3D 데이터를 어떻게 처리하고 활용할 것인가에 대한 질문을 던져주었습니다.
3D 딥러닝 역시 2D 데이터에 대한 딥러닝과 같이 classification 부터 시작하여 detection task 으로 발전하였고, 3D 데이터를 활용한 딥러닝 모델은 자율주행, 로봇, 증강/가상 현실 등과 같은 다양한 영역으로 확대되어 적용될 수 있다는 기대를 받고 있습니다.
3D 딥러닝에 관심이 있는 독자 분들에게 이번 글이 3D 딥러닝을 한 걸음 알아가게 해주는 역할을 했길 바랍니다.
References
[1] Ahmed, Eman, et al. "A survey on deep learning advances on different 3D data representations." arXiv preprint arXiv:1808.01462 (2018).
[2] Su, Hang, et al. "Multi-view convolutional neural networks for 3d shape recognition." Proceedings of the IEEE international conference on computer vision. 2015.
[3] Qi, Charles R., et al. "Pointnet: Deep learning on point sets for 3d classification and segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
[4] Qi, Charles Ruizhongtai, et al. "Pointnet++: Deep hierarchical feature learning on point sets in a metric space." Advances in neural information processing systems 30 (2017).
[5] Shi, Shaoshuai, Xiaogang Wang, and Hongsheng Li. "Pointrcnn: 3d object proposal generation and detection from point cloud." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019.
[6] Chang, Angel X., et al. "Shapenet: An information-rich 3d model repository." arXiv preprint arXiv:1512.03012 (2015).




COPYRIGHT (c) 2022 CUBOX ALL RIGHTS RESERVED
개인정보취급방침